



近日,南方科技大学统计与数据科学系讲席教授、大数据创新中心荆炳义课题组和粤港澳大湾区数字经济研究院(IDEA)认知计算与自然语言中心(CCNL)联合发布开源34B通用Chat模型:SUS-Chat-34B,在由美国Hugging Face社区支持的、致力于追踪、排名和评估大语言模型性能的开放大语言模型排行榜(Open LLM Leaderboard)中占据榜首,成为目前最具优势的开源34B指令微调模型之一。
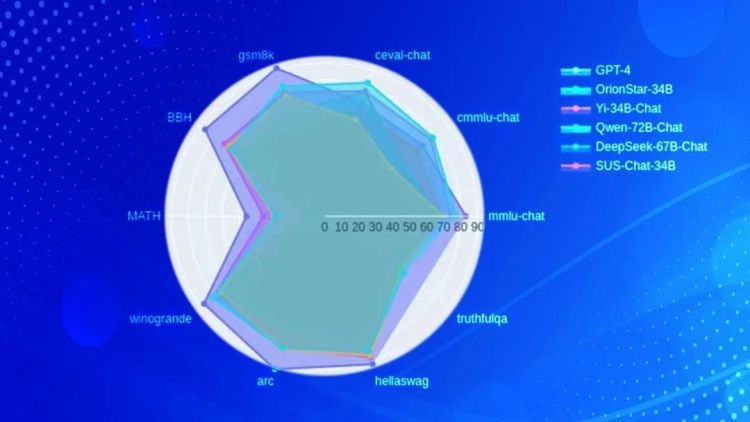
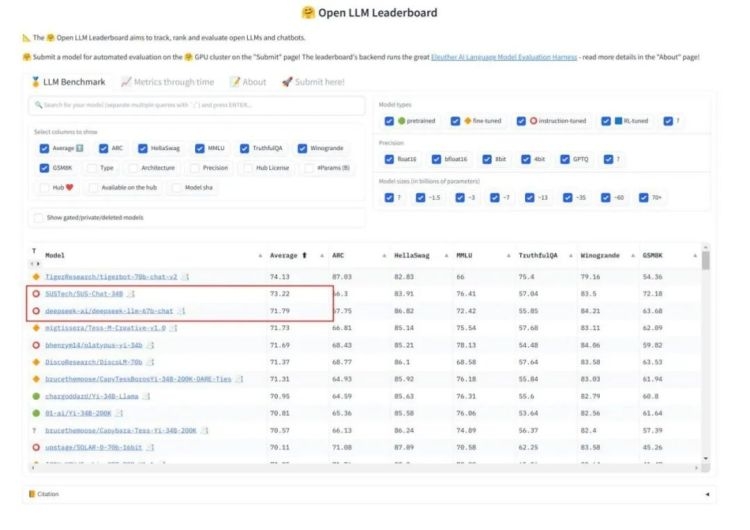
高质量训练数据迭代,助力模型综合能力提高
随着人工智能技术的快速发展,AI的多任务学习能力和泛化能力日益增强,实现AI系统目标与人类价值观和利益相对齐,成为AI研究领域中的重要议题。而指令微调往往被认为是模型能够正确接受指令给出恰当反馈、与人类面对问题的思考方式进行对齐的重要过程,也是大模型从只具有模仿能力到真正可以理解人类意图的关键步骤。指令微调涉及到高质量的人类指令数据收集和整理,对于340亿参数的模型来说,并非普通学术机构可轻易承担。
然而,在SUS-Chat-34B模型的训练中,南方科技大学大数据创新中心荆炳义课题组和CCNL中心通力合作,借由CCNL中心提供的大规模计算集群和合作开发的高性能训练框架,将整个训练的成本有效控制在了可接受的范围。荆炳义课题组在对指令数据的整理和筛选中做了大量的研究工作,根据小规模数据的实验构建了相关模型,并从中挑选出了最能提升模型思维能力尤其是逻辑能力的百万级别模型。通过这一过程,成功改善了模型对人类指令的响应方式,让模型能够通过思维链等方式模仿人类思考过程。

▲南方科技大学大数据创新中心荆炳义课题组成员。
经过南方科技大学大数据创新中心荆炳义课题组(以下简称荆炳义课题组)多日的训练,SUS-Chat-34B在几乎所有评估模型的benchmark(基础比较对象)上都有大幅度的提升,取得了同尺寸开源模型中的最高分,甚至与具有720亿参数的更大尺寸开源模型相比,也都有亮眼的表现。
在训练数据迭代的过程中,课题组采用了一种精细化的筛选方法,以提炼出与模型能力最相关的数据子集。这一过程涉及对上亿条指令文本数据的深度分析和挑选,课题组在100亿参数级别的模型上进行了快速多次实验,根据通用任务榜单的综合性能标准,确定最优的数据分布。
这样的策略使得数据组成更加精确地对应模型的发展需求,为其提供了高质量的训练资源。这种方法确保数据在数量、质量上都能符合模型提升的关键需求,特别是在增强模型的语言理解和响应能力方面。通过这种策略,模型能更有效地学习和适应复杂的语言模式和指令,从而在各种评估中表现出更高的性能和更强的适应能力。
荆炳义课题组在评测模型的关键性语言能力过程中,建立了广泛的基准测试,并开放了一个易于使用的评测框架开源TLEM工具。
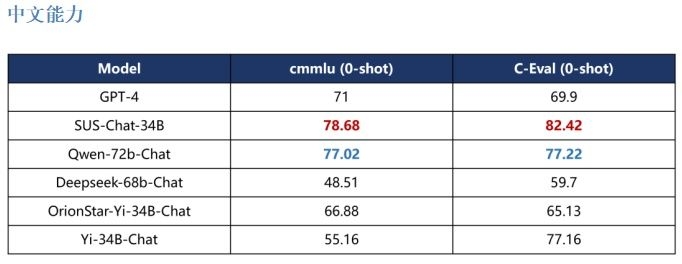
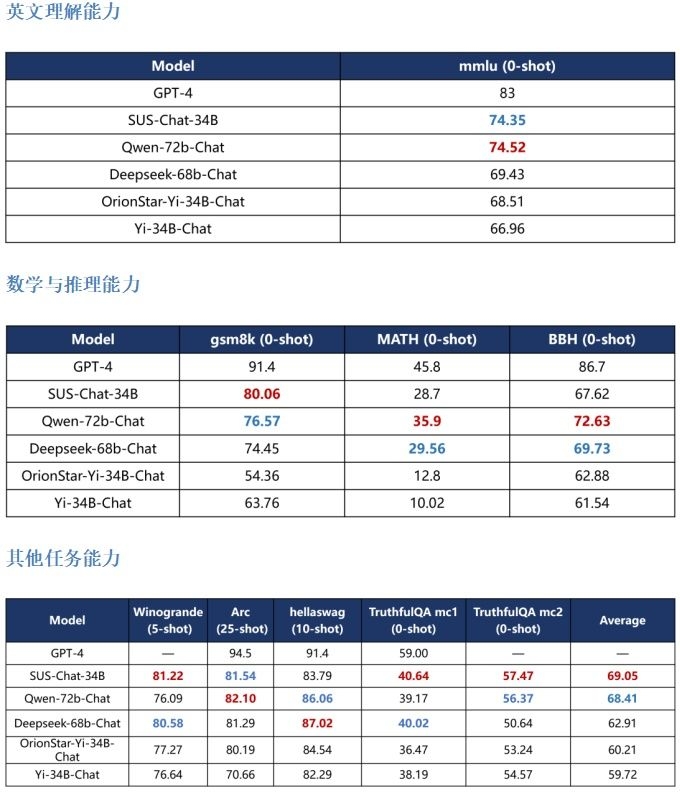
使用人类思考方式,提升模型知识问答能力
一般SFT模型相比于Few-shot的预训练模型,往往在多数benchmark(基础比较对象)上会有所下降,被称为“对齐税(Alignment Tax)”。SUS-Chat-34B模型在部分指标上也表现出了这一点,但荆炳义课题组在训练时加入了类似人类思考过程的数据,如在回答问题时先分析问题、规划解决方案,使模型在指令对齐中学会了用人类的逻辑思维方式思考。因此,SUS-Chat-34B在多数指标,尤其是涉及数理逻辑的基准测试中,通过更加正确的思考方式,有效缓解了与人类指令对齐带来的模型性能降低,甚至在部分基准测试中获得了相比于预训练模型Fewshot更高的得分。这一现象打破了工业界大型语言模型训练中“对齐税普遍存在”的认知,为模型训练提供了新的思路和借鉴。
SUS-Chat-34B模型在HuggingFace Open LLM Leaderboard上取得了34B模型上最好的成绩,在全部模型中仅次于榜单第一名的tigerbot-70B-Chat。此外,在权威推理评测集GSM8k中,SUS-Chat-34B在所有模型中排名第一,超过了仅用MetaMathQA数据集微调的MetaMath-Mistral-7B,这充分说明了模型思维能力的提升对模型在各项涉及逻辑的基准测试中的表现所起到的重大影响,同时也有力证明了对齐阶段不只有与“对齐税”带来的代价,更有因为与人类思维方式对齐带来的性能提升。
解决模型开发常见问题,有效提升模型长文本与多轮对话能力
在开发先进的开源对话大型模型时,如何在多轮对话中维持对相关文本的持续关注,同时避免对无关文本的过度关注,是开发者常常会遇到的问题。这个问题也成为了提高多轮对话性能的关键。为了解决这一问题,课题组在模型训练阶段采取了一种创新性方法:指令间共享注意力机制。
这种方法的核心是允许不同对话轮次之间的注意力机制部分共享,从而使模型在微调阶段能够同时捕捉到与相关多轮对话数量相当的非相关多轮对话数据。这种机制的引入显著优化了模型处理多轮对话时对不同内容的关注分布。
通过这种注意力机制共享的方法,模型能够更有效地区分和响应多轮对话中的关键内容。在具体实现上,这一机制通过调整注意力权重的分配,让模型在处理连续对话轮次时,能够更准确地识别和保持对于先前轮次中重要信息的关注。不仅提高了模型对于上下文的理解能力,也增强了其在复杂对话场景中的应对能力。
该项目由南方科技大学统计与数据科学系讲席教授、大数据创新中心荆炳义、课题组研究学者南科大2018级校友谢泽健、张松昕,IDEA研究院认知计算与自然语言研究中心相关算法负责人宋卓洋、资深算法研究员何峻青牵头完成。

▲南方科技大学大数据创新中心荆炳义课题组成员,前排林聪(左)、荆炳义教授(中)、张松昕(右),后排宋卓洋(左)、谢泽(右)。
▍相关链接 ▍
★统计与数据科学系★
南方科技大学统计与数据科学系成立于2019年4月,以建设国际一流的教育培养和研究基地为目的。本系志在为国家培养出具有扎实的科学基础,思想活跃,创新意识和能力强,有国际视野,脚踏实地,有朝气、有理想的拔尖人才。该系已经建立起本硕博人才培养体系,拥有统计学和数据科学与大数据技术两个本科专业,及数学学科下概率论和数理统计硕博学位授予权,主要研究领域包括数理统计、生物医学统计、金融统计和数据科学。
该系目前共有17位教研序列教师和4位双聘教师,其中有讲席教授3人,教授4人,副教授5人,助理教授9人。统计系拥有国际化、高水平的师资队伍,包括1名国际数学家大会邀请报告人,2名国家自然科学奖二等奖获得者,1名长江讲座教授,2名国际数理统计学会(IMS)会士,1名IMS常务理事,1名美国统计学会(ASA)会士,1名IMS Medallion讲座演讲者,1名英国皇家统计学会会士、1名英国计算机学会会士,1名广东省特支科技创新青年拔尖人才,1名深圳市杰出人才培养对象和2名深圳市优秀教师。
该系充分利用学校及学院的优势,汇聚优质教学资源。目前已建立起生物医学统计中心、大数据创新中心和统计咨询中心,未来将会建立大数据分析统计理论研究中心和金融统计中心等,加强统计与数据科学学科的研究和创新,为学生提供良好的学习环境和科研平台。
★大数据创新中心★
大数据创新中心依托于南方科技大学统计与数据科学系建立,目标建设符合国家经济发展需求和深圳市学科布局一流的大数据科学研究基地及数据产业孵化基地。
该创新中心研发重点包括:
机器学习与人工智能、大数据分析、网络科学、金融大数据、生物医疗大数据、统计方法等。

▲南方科技大学大数据创新中心荆炳义课题组成员。
★大数据创新中心主任荆炳义简介★

荆炳义讲席教授
荆炳义讲席教授是美国统计协会(ASA)和数理统计协会(IMS)会士(Fellow),国际统计学会(ISI)当选会士,泛华统计协会理事会成员,并先后分别担任七家国际期刊副主编;曾荣获2015年度国家自然科学奖二等奖, 教育部长江学者讲座教授,及两年度(2010,2015)获教育部高等学校自然科学奖二等奖。
荆炳义教授于1993年在悉尼大学获得统计学博士学位;1992-1994 年在澳洲国立大学做博士后,师从国际著名统计学家 Peter Hall 教授;1994-2021年在香港科技大学工作,任数学系教授、统计科学中心主任;现任南方科技大学统计与数据科学系副系主任、讲席教授,大数据创新中心主任,多元分析应用分会第八届理事会理事长。
荆炳义教授研究兴趣广泛,包括概率论与数理统计,金融计量及高频数据分析,机器学习理论与算法,生物信息,网络数据分析,强化学习等。他在各领域中有许多开创性研究,取得了很多突破性科研成果。共发表论文 100余篇,被引用3500 余次(Google Scholar)。许多学术论文发表在国际顶尖杂志上,包括统计方向四大顶尖杂志 (Annals of Statistics, Journal of American Statistical Association, Biometrika, Journal of Royal Statistical Society B),概率方向顶尖杂志 (Annals of Probability, Probability Theory and Related Fields, Bernoulli),金融计量顶尖杂志 (Journal of Econometrics, Journal of Business & Economic Statistics) , 生 物 信 息 顶 尖 杂 志 (Bioinformatics),国内顶刊《中国科学》(Science in China)等。
